
Nell’area Impostazioni –> Nodi, sarà possibile accedere all’aggiornamento del nodo tramite file in formato csv.
ATTENZIONE: Prima di eseguire qualsiasi operazione, suggeriamo vivamente di effettuare dei test su nodi o workspace di prova.
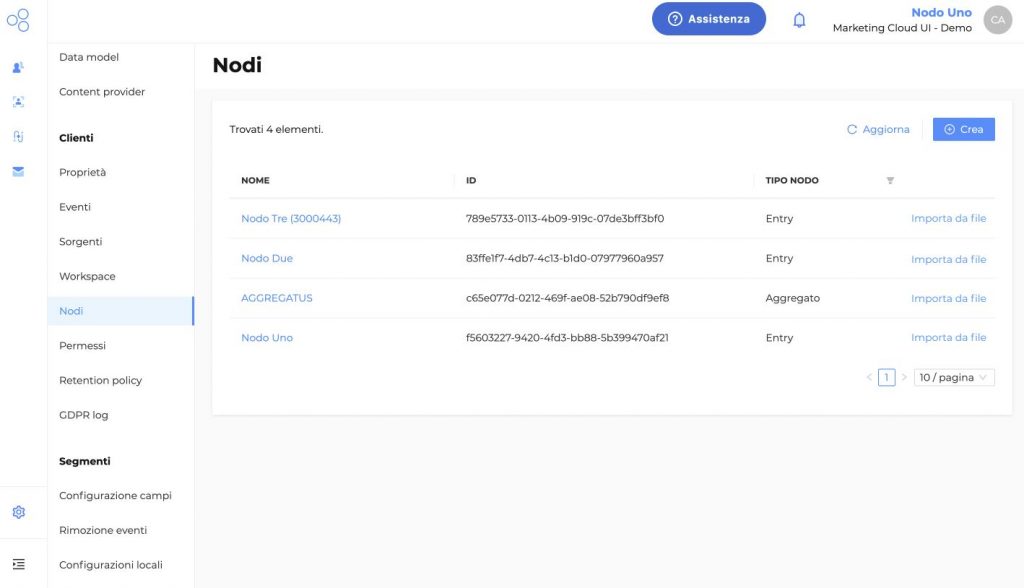
Nella pagina Importa da File, sarà possibile monitorare i processi di importazione schedulati o eseguiti con relativo stato. E’ inoltre possibile scaricare un report dell’operazione effettuata
Vengono mostrati i dati degli ultimi 30 giorni.
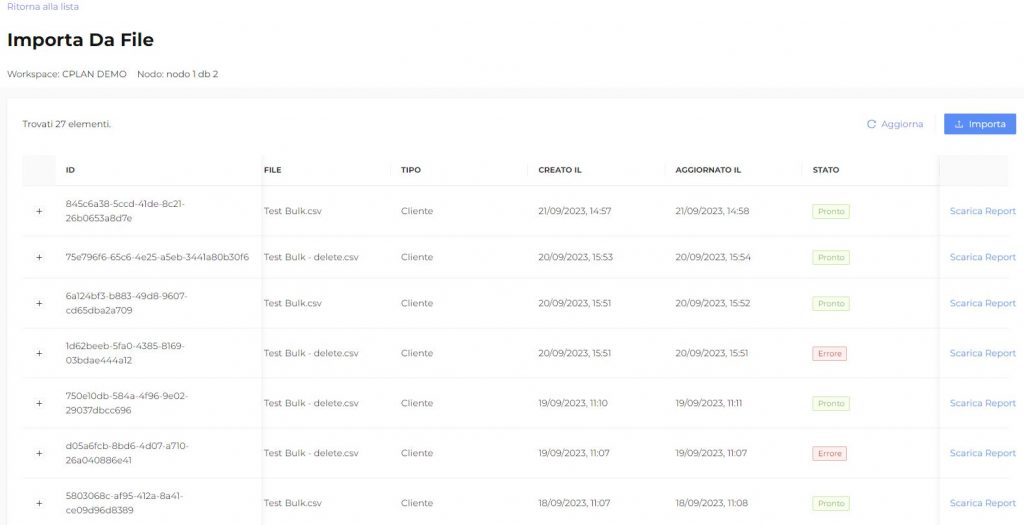
Importazione file
L’area di importazione prevede di selezionare:
- il tipo dato da aggiornare tra Customer o Eventi
- il tipo di operazione: Inserimento (o aggiornamento nel caso l’utente sia presente) oppure Cancellazione per i Customer, solo Inserimento per gli Eventi
- Il tipo di evento da inserire (solo in caso di caricamento Eventi)
Clienti
INSERIMENTO/AGGIORNAMENTO
L’inserimento dei customer prevede il caricamento di un file con corrispondenza esatta ai json path delle proprietà del json-schema del customer.
E’ mandatorio inserire nel file i campi configurati sul nodo come criterio di unicità del cliente e i campi indicati come obbligatori.
Anche per le proprietà di tipo array (ad eccezione delle subscriptions) è necessario specificare esattamente il json path delle proprietà del json-schema del customer (es. tags).
Di seguito sono riportati degli esempi per array di scalari:
tags.manual,tags.auto
Per quanto riguarda le subscriptions, gli header devono includere l’ID della subscription e la proprietà che si intende valorizzare sotto forma di json-path (es. base.subscriptions.SUBSCRIPTION_ID.subscribed).
Di seguito sono riportati degli esempi per le subscriptions:
base.subscriptions.SUBSCRIPTION_ID_1.subscribed,base.subscriptions.SUBSCRIPTION_ID_1.name,base.subscriptions.SUBSCRIPTION_ID_2.subscribed,base.subscriptions.SUBSCRIPTION_ID_2.subscribeContext.ip
Per ogni subscription ID la proprietà subscribed è obbligatoria. Se non dovesse essere presente verrà lanciata un’eccezione e il job andrà in stato FAILED.
Non è possibile inserire i seguenti header all’interno del file csv:
intId (e gli altri campi “di sistema” in quanto generati da hub)
nodeId (già presente nella rotta)
extra
base.likes, base.educations, base.jobs, base.socialProfile, base.contacts.mobile_devices, base.contacts.other_contacts (in quanto deprecati).
Headers disponibili:
externalId
base.pictureUrl
base.title
base.prefix
base.firstName
base.lastName
base.middleName
base.gender
base.dob
base.locale
base.timezone
base.contacts.email
base.contacts.fax
base.contacts.mobilePhone
base.contacts.phone
base.address.street
base.address.city
base.address.country
base.address.province
base.address.region
base.address.zip
base.address.geo.lat
base.address.geo.lon
base.credential.password
base.credential.username
base.subscriptions.ID.id
base.subscriptions.ID.subscribed
base.subscriptions.ID.name
base.subscriptions.ID.type
base.subscriptions.ID.kind
base.subscriptions.ID.startDate
base.subscriptions.ID.endDate
base.subscriptions.ID.subscriberId
base.subscriptions.ID.registeredAt
base.subscriptions.ID.updatedAt
base.subscriptions.ID.subscribeContext.ip
base.subscriptions.ID.subscribeContext.userAgent
base.subscriptions.ID.unsubscribeContext.ip
base.subscriptions.ID.unsubscribeContext.userAgent
base.subscriptions.ID.unsubscribeContext.campaignId
base.subscriptions.ID.unsubscribeContext.campaignMessageId
consents.disclaimer.date
consents.disclaimer.version
consents.marketing.traditional.telephonic.status
consents.marketing.traditional.telephonic.limitation
consents.marketing.traditional.telephonic.objection
consents.marketing.traditional.papery.status
consents.marketing.traditional.papery.limitation
consents.marketing.traditional.papery.objection
consents.marketing.automatic.sms.status
consents.marketing.automatic.sms.limitation
consents.marketing.automatic.sms.objection
consents.marketing.automatic.email.status
consents.marketing.automatic.email.limitation
consents.marketing.automatic.email.objection
consents.marketing.automatic.push.status
consents.marketing.automatic.push.limitation
consents.marketing.automatic.push.objection
consents.marketing.automatic.im.status
consents.marketing.automatic.im.limitation
consents.marketing.automatic.im.objection
consents.marketing.automatic.telephonic.status
consents.marketing.automatic.telephonic.limitation
consents.marketing.automatic.telephonic.objection
consents.profiling.classic.status
consents.profiling.classic.limitation
consents.profiling.classic.objection
consents.profiling.online.status
consents.profiling.online.limitation
consents.profiling.online.objection
consents.softSpam.email.status
consents.softSpam.email.limitation
consents.softSpam.email.objection
consents.softSpam.papery.status
consents.softSpam.papery.limitation
consents.softSpam.papery.objection
consents.thirdPartyTransfer.profiling.status
consents.thirdPartyTransfer.profiling.limitation
consents.thirdPartyTransfer.profiling.objection
consents.thirdPartyTransfer.marketing.status
consents.thirdPartyTransfer.marketing.limitation
consents.thirdPartyTransfer.marketing.objection
tags.manual
tags.auto
enable
Più le estese configurate nel workspace.
Ad esempio:
extended.custom-number
extended.custom-integer
extended.custom-number-array
extended.custom-integer-array
extended.custom-date-array
extended.custom-date-time-array
CANCELLAZIONE
I file per la cancellazione dei clienti devono contenere come unico header l’id e tutti gli id inseriti uno per ciascuno linea.
Esempio:
id
a31687a0-1fc8-11ee-8469-97544ea1cf7b
a6fd6348-1fc8-11ee-99a9-ebc7f741dc11
Eventi
INSERIMENTO
Per gli eventi l’unica operazione massiva possibile è l’inserimento.
E’ presente una opzione aggiutiva rispetto ai customer che riguarda la scelta del tipo di evento da importare (un file può contenere solo eventi dello stesso tipo e corrispondenti a quello dichiarato).
L’inserimento degli eventi prevede il caricamento di un file con corrispondenza esatta ai json path delle proprietà del json-schema dell’evento selezionato.
I file contenenti eventi che non contengono un array di prodotti (quindi non di tipo completedOrder o abandonedCart) vengono inseriti normalmente con un evento per ciascuna riga, per esempio con un formCompiled potrebbe essere:
customerId,context,date,propeties.formName,properties.formId,properties.data
1c60bede-5703-11ee-add1-e3a3ea94c53f,WEB,2023-09-19T15:42:32.229Z,vacanze,5703,2023-09-19T15:42:32.229Z
Per i file per eventi con context info dinamico bisogna inserire i valori nelle colonne corrette altrimenti l’evento costruito sarà invalido rispetto allo schema:
customerId,context,properties.contextInfo.client.userAgent,properties.contextInfo.salesAssistant.firstName,properties.contextInfo.store.name
1c60bede-5703-11ee-add1-e3a3ea94c53f,MOBILE,Firefox,,
3654f396-5703-11ee-a06d-ef911bcd288a,RETAIL,,Marco,
a0a01992-5703-11ee-b323-7342033685cb,ECOMMERCE,,,Negozio-Grande
Per i file per eventi con array di prodotti, (completedOrder, abandonedCart), necessitano di esplicitare anche le caratteristiche dei prodotti oltre che a quelle dell’evento.
Per aggiungere i prodotti ad un evento, questi vanno inseriti ognuno su una riga segnalandoli con il recordType products che indica ad hub che questi sono elementi dell’array products dell’evento soprastante.
Tutti i prodotti di un evento vanno inseriti uno in seguito all’altro sotto alla riga dell’evento a cui appartengono, come nell’esempio sottostante (abandonedCart):
recordType,customerId,date,properties.orderId,properties.products.subtotal
abandonedCart,1c60bede-5703-11ee-add1-e3a3ea94c53f,OID01,
products,,,42
products,,,43
Formato dei valori
Ogni linea del csv deve contenere i valori per le proprietà di una singola entità. Le linee vuote saranno considerate errori.
Le configurazioni di default del file csv sono:
- separator character→ , è il carattere che separa una colonna dalla successiva
- quote character → ” è il carattere che indica l’inizio e la fine di una proprietà
- escape character → \ è il carattere utilizzato per inserire caratteri speciali come quelli riportati sopra
- il continuation character è disabilitato
Di seguito sono elencate le regole per l’inserimento dei valori:
- i valori di tipo stringa possono essere inseriti sia tra doppi apici che senza. Se la stringa contiene a sua volta dei doppi apici allora è obbligatorio inserire la stringa fra doppi apici o escaparli con il carattere \. Esempi (csv → String):
- esempio → “esempio”
- “esempio” → “esempio”
- “”esempio”” → “\”esempio\””
- “\”esempio\”” → “\”esempio\””
- per inserire un numero dispari di ” all’interno di una stringa bisogna anticiparli con altri doppi apici. È consentito anche usare il \ come carattere di escape per il ” . Esempi:
- “monitor 24″”” → “monitor 24\””
- “monitor 24\”” → “monitor 24\””
- per inserire un valore stringa vuota bisogna utilizzare 2 doppi apici consecutivi: es. “”
- i valori degli header tipo array devono essere inseriti in un’unica colonna e divisi attraverso il simbolo pipe | . Esempi (csv → json):
- tag01|tag02|tag03 -> [“tag01″,”tag02″,”tag03”]
- per inserire nell’array un valore contenente il simbolo del pipe | è necessario escaparlo con un backslash \. Esempi (csv → json):
- esempio 01|esempio \| 03|esempio 04 -> [“esempio 01″,”esempio | 03”, “esempio 04”]
- i valori array vuoto possono essere inseriti sia con [] che con “[]” o con due separatori consecutivi (es. ,,)
- i valori NULL possono essere inseriti sia con null che con “null” o con due separatori consecutivi (es. ,,)
- pertanto non è possibile inserire la stringa “null”
- proprietà numeriche possono essere inserite tra “. Esempi:
- “24” → 24
- “24.5” → 5
- si possono inserire stringhe multilinea utilizzando i doppi apici aggiungendo il carattere di newline opportunamente escapato \\n in quanto il controllo di validità (parità ) delle ” viene effettuato sulla singola riga, esempio:
- headerInt1,headerInt2,headerStr3,headerInt4
1,2,”stringa che \\n continua a capo”,4
- headerInt1,headerInt2,headerStr3,headerInt4